I agree and didn't intend to imply that
The Xenon shines as a Low-Powered device. I absolutely love it.
The only time a Xenon (edge device, endnode, sensor node, etc) needs to connect to the Gateway is when it need to push data to the outside world.
Thus the suggestion to not have 55 devices continuously on the Mesh at any one time, it only complicates things. Users will get much better performance having Xenons join the mesh only when necessary to push data to the outside world. Only the Gateway and the Xenons required to develop the physical service area should remain on the Mesh Network. You still have a 55 device network, they normally don't have any reason to all be on the Mesh at once.
IMO, the leader is Digi. Take a look at XCTU.
The Particle topology tools dont need to be as elaborate, but we do need a quick way to ask a Xenon what other Gen3 devices are within it's radio range, especially during the original deployment for the "routers".
I appoligize if I sound like I'm preaching.
I promise that's not my intention.
Just sharing experience that I learned the Hard Way over the years with other Mesh Networks.
Sounds like I should just have the devices disconnect on setup, reconnect to the Mesh when I need to pass data back to the gateway. The issue with this right now is that I want to push as much data as possible so is there a lower limit where this doesn’t make sense?
Ex. if I am pushing every 10 seconds (as an example), then there is time to reconnect to the network, and I have to make sure every device is online to get the data back to the gateway. Does it make sense to
disconnect from the network
reconnect
check there is a connection
send the data
get the response back from the gateway
then have some buffer to make sure there is no other data coming across from other Xenons in the network
and then go to sleep
This is my first mesh network so learning on the fly. Thanks everyone, this is turning into a great, little thread.
@armor and @Rftop, a single gateway topology definitely calls for a planning an measuring tool and we have been pushing for this on both the Elite and G3CC sides. Besides the obvious need for HA, I also believe there is a need for a Xenon bases mesh bridge to allow two meshes to connect. With a gateway on each mesh to keep traffic-per-gateway low, a bridge would also allow for a mesh to fall back to the connected mesh as another type of HA.
I totally support the idea of creating a Xenon repeater “backbone” first then adding Xenon endnodes to those. That is simply good mesh planning IMO which I have been preaching since day one (). Having sleepy-node capability will add one of the key missing pieces in addressing “larger” meshes.
The biggest mistake I see if folks making is treating mesh like a high speed network, which it is not. Something that has not been discussed is data aggregation at backbone nodes for processing and passing upstream to reduce data bandwidth. BTW, a Particle.publish() from a node still uses an underlying Mesh.publish()-like transmission except that the data needs to get to a gateway to make its way to the Cloud. So consideration of ALL data over the 250Kbps bandwidth of a mesh is a key factor. This is a major concern when trying to apply OTA to mesh devices simultaneously as the data can quickly swamp the mesh, especially if it’s already loaded. OTA to mesh may need a “smarter” sequenced approach which has not been discussed as of yet.
I just want to say thank you t @emile for starting this area of exploration and to his time devoted to testing different ideas!
I recently explained a Mesh Network like this:
A Mesh has limited Bandwidth ( a lot is used for Network Overhead), but unlimited Time on it's hands.
Just do what you can to space out your traffic....there's plenty of time in a day.
Is there a best practice around calculating Used vs Open bandwidth in a mesh network? Maybe a packet sniffer for mesh networks?
I’m passing a lot of small strings over my mesh network, and rather than guessing, I should get into the weeds and fully understand how data is going across the network.
@emile, there is no packet sniffer and no overhead calculator as of yet. We have been pushing Particle to create mesh management tools for a while now.
Remember that every publish is essentially a UDP multicast so what has been mentioned in terms of “backbone” Xenons can come into play here. The ideal number of neighbours is 2-4 to limit the scope of the multicast. If you have all the devices adjacent to each other, the multicast may hit them all, creating a bit of a “storm”.
I would look at your data requirements - how often, how much, can it be aggregated over a period and then sent forward, can it be averaged, etc. How is the collected data used? Etc.
Seems like the perfect use case for @rickkas7 PublishQueueAsyncRK library where you can blast out your buffered data all at once or send it out in chunks on a preset timed interval to avoid flooding.
I’m finding OTAs to be a little tricky with so many devices on the network.
Currently
All of my edge devices are disconnected from Particle 99% of the time. When I need to, I run a bash script that hits a function on my gateway that publishes a message to wake up a particular device.
# # Conect to Particle
for device in $devices
do
curl https://api.particle.io/v1/devices/<gateway>/particle-connect \
-d access_token=<token> \
-d "args=$device"
printf "\n"
sleep 10
done
sleep 120
# Deploy new code
for name in $names
do
particle flash $name prod-transmitter.ino
done
echo All done
Then on my Xenons:
// On my Gateway
Particle.function("particle-connect", connectEdgeToParticleCloud);
// -----------------------------------------------------------------------------
int connectEdgeToParticleCloud(String deviceID)
// -----------------------------------------------------------------------------
{
if (deviceID != "") {
Mesh.publish("particle-connect", deviceID);
return 1;
} else {
Serial.println("Need a deviceID to connect");
return 0;
}
}
// On the Edge
Mesh.subscribe("particle-connect", handleParticleConnect);
// -----------------------------------------------------------------------------
void handleParticleConnect(const char *event, const char *deviceID)
// -----------------------------------------------------------------------------
{
if (strcmp(deviceID, System.deviceID()) == 0) {
Particle.connect();
}
}
Problems
I’m having a few problems with this setup:
Because all of the devices on the network cannot connect to Particle at once, I have to batch the deploys. This isn’t so much a problem but it does slow it down.
After I send the command to wake up the device, I do not know if/when the Xenon has connected to Particle.
This means some of the flash commands timeout because the device is not online
Putting a delay in the bash script isn’t very elegant (for the purpose above)
Finally some never connect to Particle. They get into a bad state and just keep trying to connect for eternity. (I will be changing my reset function to hopefully address this).
This solution works ~80% of the time. However once I put a device infield, I’m concerned about these devices getting out of sync.
Any ideas on a better solution?
EDIT:
I’ve updated the script which seems to help. This will disconnect devices after the flash. That way there shouldn’t be any other edge devices connected to Particle. The more devices connected to Particle on the network, the slower it has been for others to connect to Particle.
# # Conect to Particle
for device in $devices
do
curl https://api.particle.io/v1/devices/<gateway>/particle-connect \
-d access_token=<token> \
-d "args=$device"
sleep 90
particle flash $name prod-transmitter.ino
sleep 30
curl https://api.particle.io/v1/devices/<gateway>/particle-disconnect \
-d access_token=<token>
done
echo All done
General approach/problems:
I have assumed sleepy and mesh connected devices as my starting point. All edge devices typically wake and send a heartbeat message to the gateway and then wait a short period of time for a command and if none is received then go back to sleep. One such command is “ota” which can be sent by the gateway and and instructs the endnode to enableOTA and to stop all other activity and connect to the Cloud. The endnode then just waits to receive the flash and afterwards will reset and go back to doing its normal cycle.
The gateway has to maintain a list of all known nodes and queue commands such as “ota” and send such commands as devices wake and check-in for any commands. It could listen for flash/enabled messages from a specific device and not enable another endnode for flash until the previous one had finished - this would stage the process - i.e. manage the lower bandwidth. Warning: I have only tried this process with one device so far!
The control for the script on flashing could be done on the receipt of a ‘particle/flash/enabled’ message.
A couple of things in your code if (strcmp(deviceID, System.deviceID()) == 0)
would be safer as if (strncmp(deviceID, System.deviceID(), 24) == 0)
I would also use Const Char* rather than String in int connectEdgeToParticleCloud(String deviceID)
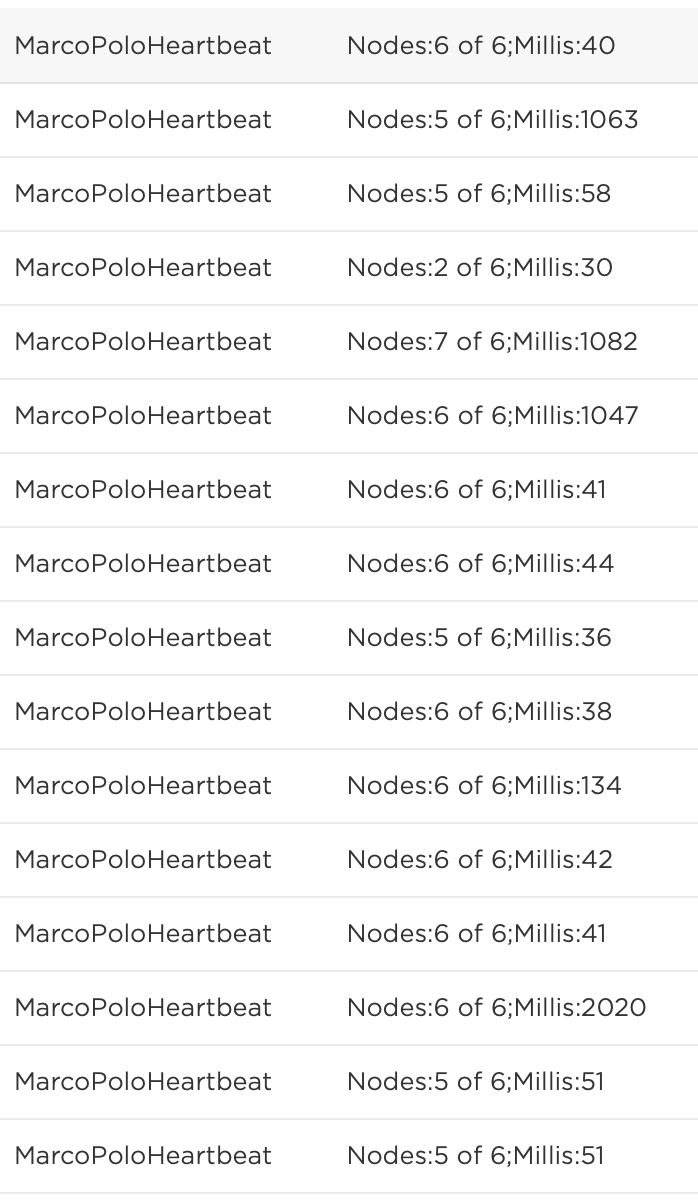
I just flashed MarcoPolo on a 6 of them. The gateway is Marco, the edge devices Polo. I believe this is right?
The devices are going to sleep for the remainder which isn’t what I’d expect. However here are the results right now. I’d like to test it without them going to sleep. Will dig into that this afternoon.
MAX_MESH_NODES was set at 10, so I’ve changed that to 6. I’m not sure why 7 showed up, that is very odd. I’ll keep playing with it today. It seems like the sleep behavior is causing the nodes to miss signals and that is why there isn’t a consistent 6/6. As for the response time, that does seems odd.
MAX_MESH_NODES just sets the array size for storing the information. Looks like you have a working Marco-Polo setup. You may have been on another topic about the gateway stability - I am still seeing the gateway lose its cloud connection (but it is not losing the Mesh and with a reasonable cloud publish buffer I can now see this).
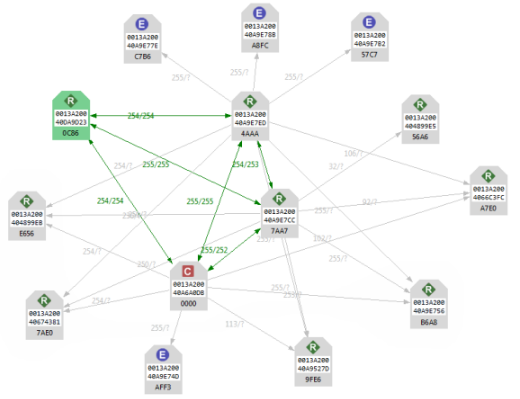
 ). Having sleepy-node capability will add one of the key missing pieces in addressing “larger” meshes.
). Having sleepy-node capability will add one of the key missing pieces in addressing “larger” meshes.